介紹#
S3 是 AWS 提供的物件儲存服務,簡單來說也就是一個檔案儲存服務。 這篇文章將會讓你了解如何使用 AWS 的 Python SDK boto3 操作 S3 API,實現檔案上傳功能,並深入探討 S3 提供的 Multipart Upload 機制,包括其概念、優勢與使用方式。
S3 的儲存結構主要由 Bucket 和 Object 組成:
- Bucket:儲存空間的管理單位,類似硬碟,可設定存取權限與儲存策略。
- Object:實際儲存的檔案,每個 Object 由一個唯一的 Key 標識,本質上類似於檔案路徑,例如 folder1/folder2/file.txt。
開始之前,先確保已安裝 boto3,這是操作 AWS API 的 Python 工具:
pip install boto3
在 boto3 中,可以使用高階(high-level)和低階(low-level)API。
- 低階 API:每個 function call 直接對應 AWS 服務的 HTTP API,提供更細緻的操作控制。
- 高階 API:在低階 API 基礎上封裝,使用更簡潔的介面完成常見任務。
使用高階 API 上傳檔案#
以下範例展示如何利用 boto3 API 將檔案上傳到 S3。
首先,我們需要建立一個 S3 的客戶端(client),並主要設定 endpoint 和 access key/secret key。
import boto3
from boto3.s3.transfer import TransferConfig, KB
import os
endpoint = os.getenv('ENDPOINT')
bucket_name = os.getenv('BUCKET_NAME')
access_key_id = os.getenv('ACCESS_KEY_ID')
secret_key = os.getenv('SECRET_KEY')
# Create a session with the specified credentials
session = boto3.session.Session(
aws_access_key_id=access_key_id,
aws_secret_access_key=secret_key
)
# Create an S3 client with the specified endpoint
s3_client = session.client('s3', endpoint_url=endpoint)
Endpoint 是指向 S3 伺服器的地址。由於 S3 API 已成為物件儲存的廣泛標準,不僅 AWS 提供的 S3 服務使用此 API,許多其他雲端儲存解決方案也提供兼容的 S3 API 服務。這意味著,我們可以透過設定 endpoint 來指定目標伺服器的位置,進而使用 boto3 操作這些兼容的服務。
config = TransferConfig(
multipart_threshold=KB * 25,
max_concurrency=10,
multipart_chunksize=1024 * 25,
use_threads=True)
objectKey = "file.txt"
# Perform the multipart upload
with open("file.txt", 'rb') as file:
s3_client.upload_fileobj(file, bucket_name, objectKey, Config=config)
使用 High-Level API 上傳檔案非常簡單,只需一行程式碼即可完成。我們只需提供 Bucket 名稱 和 Object Key,即可將檔案順利上傳至 S3。
Multipart Upload#
在這裡,我們額外套用了 transfer config,以啟用 Multipart Upload 機制。
Multipart Upload 是 S3 API 提供的一種上傳機制,簡單來說,它將一個大檔案分割成多個小區塊(parts),並分段上傳。

根據 AWS 文件的說明,這種機制具有以下優勢:
- 提升效率:透過將每個 part 平行化上傳,顯著提高大檔案的上傳速度。
- 提高可靠性:避免因網路或伺服器問題導致整個檔案上傳失敗,因為每個區塊可以獨立重傳。
- 即時處理:當應用中的使用者上傳大檔案時,可直接處理接收到的分段檔案,而無需等待整個檔案完成上傳。
Multipart Upload 的操作流程#
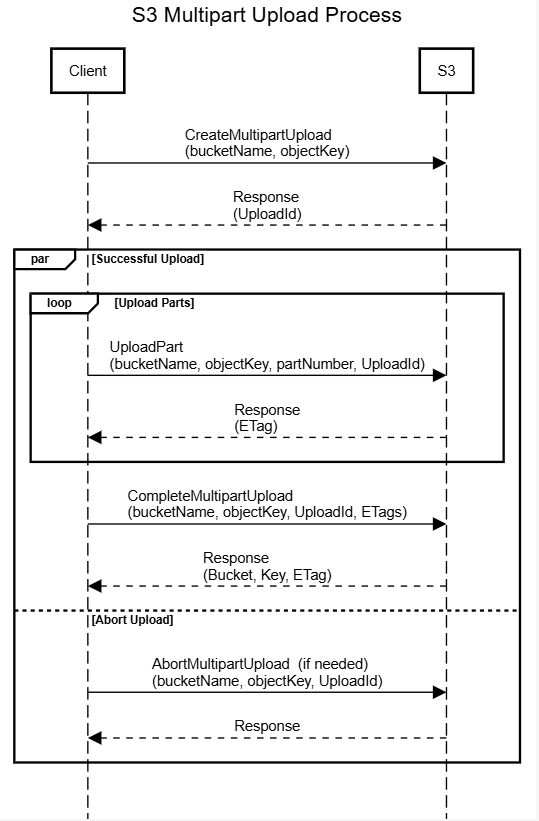
從 S3 API 的角度來看,使用 Multipart Upload 進行檔案上傳,需要以下三個步驟:
建立上傳任務:使用 CreateMultipartUpload 指定上傳路徑(Object Key),建立上傳任務。此時,S3 會回傳一個唯一的 uploadId,用於識別該上傳任務。
分段上傳:程式將檔案分割為多個小區塊,並使用 UploadPart 上傳每個區塊:
- 每個區塊有一個唯一的 partNumber,由程式決定。
- partNumber 不需要連續,但最終必須按順序排列。
- 各區塊可平行上傳,無需等待前一個區塊完成。
完成上傳:最後,呼叫 CompleteMultipartUpload,將 S3 會將所有區塊合併成完整檔案,並完成上傳。
中斷與清理機制#
若上傳任務中斷或失敗,部分已上傳的區塊會被保存在 Object Storage 中,這些稱為 incomplete multipart uploads。它們會占用存儲空間,因此需定期清理:
我們可以主動呼叫 AbortMultipartUpload 取消上傳任務並刪除無效區塊。
AWS 也提供 Lifecycle Policies 來設定定時清除 incomplete multipart uploads。
當然,boto3 的高階 API 已經將整個 multipart upload 的過程封裝起來,使用者不需要自己去管理 multipart upload 的過程,只需要把檔案傳給 boto3 並設定好 transfer config,他就會自動透過 multithreading 來完成多個區塊的上傳。
透過低階 API 實現 Multipart Upload#
當然,我們也可以透過 boto3 提供的低階 API 來,自行完成分片跟上傳。
在低階 API 中,每個 S3 API 請求對應到一個 boto3 的 function call。
response = s3_client.create_multipart_upload(Bucket=bucket_name, Key=objectKey)
upload_id = response['UploadId']
首先,我們使用 create_multipart_upload 建立一個上傳任務,並取得對應的 uploadId。
parts = []
with open(filename, 'rb') as file:
for i in range(1, num_parts + 1):
part_data = file.read(part_size)
response = s3_client.upload_part(
Bucket=bucket_name,
Key=objectKey,
PartNumber=i,
UploadId=upload_id,
Body=part_data
)
parts.append({'PartNumber': i, 'ETag': response['ETag']})
接著我們讀取要上船的檔案,並將檔案分割成多個區塊,透過 upload_part 逐一上傳。
response = s3_client.complete_multipart_upload(
Bucket=bucket_name,
Key=objectKey,
UploadId=upload_id,
MultipartUpload={'Parts': parts}
)
最後,我們使用 complete_multipart_upload 完成上傳,我們可以同時帶上每個 Part 上傳後的 ETag,以確保所有區塊都已成功上傳,在MultipartUpload={'Parts': parts}中我們還可以帶上每個 Part 的 Checksum 或著提供整個檔案的 Checksum,以確保檔案的完整性。
如果中途上船失敗了,我們可以呼叫 s3 的 AbortMultipartUpload 來取消上傳任務,並刪除已經上傳的區塊。
# Abort the multipart upload
response = s3_client.abort_multipart_upload(
Bucket=bucket_name,
Key=object_key,
UploadId=upload_id
)
總結#
今天我們介紹了 S3 的 python SDK boto3,並且深入探討了 S3 的 Multipart Upload 機制,透過 Multipart Upload,我們可以更有效率地上傳大檔案,提高可靠性,並且即時處理檔案。 當然更加詳細的使用說明,可以參考 AWS S3 和 boto3 的文件。