前言#
這個系列是 2022 年參加 ithome 鐵人 30w 競賽的產物,參賽主題是“教練我想玩 eBPF“,因為近年來 eBPF 成為 cloud native 的一個熱門話題,在 COSCUP2022 還有一些 meetup 的活動都在討論這個議題,因此希望能夠找個機會來學習這項技術,借助這個比賽的機會,來學習和整理 eBPF 的知識,比賽結束後將這三十天的產出重新整理後重新發表,成為本“學習 eBPF 系列”。
本系列文章主要是兩個部分,首先是針對 eBPF 的一些基本語法、架構和用法的基本介紹。接著透過 trace bcc 這個 eBPF 的開發框架的許多範例原始碼,來了解 eBPF 的用途和實例,最後簡單介紹一下所有的 eBPF 裡面很重要的 helper functions。
eBPF 的前身#
要介紹 eBPF 勢必得先聊聊 eBPF 的前身 Berkeley Packet Filter (BPF),BPF 最早是在 1993 年 USENIX 上發表的一個在類 Unix 系統上封包擷取的架構。
由於封包會持續不斷的產生,因此在擷取封包時,單一個封包的處理時間可能只有幾豪秒的時間,又封包擷取工具的使用者通常只關注某部分特定的封包,而不會是所有的封包,因此將每個封包都丟到 User space 來處理是極為低效的行為,因此 BPF 提出了一種在 kernal 內完成的封包過濾的方法。
簡單來說,BPF 在 kernal 內加入了一個簡易的虛擬機環境,可以執行 BPF 定義的指令集,當封包從網卡內進入的時候,就會進到 BPF 的虛擬機,根據虛擬機的執行結果來決定是否要解取該封包,要的話再送到 user space,因此可以直接在 kernal 過濾掉所有不必要的封包。
大家最常使用的封包過濾工具應該是 tcpdump ,tcpdump 底下就是基於 BPF 來完成封包過濾的,tcpdmp 使用了 libpcap 這個 library 來與 kernal 的 BPF 溝通,當我們下達 tcpdump tcp port 23 host 127.0.0.1 這樣的過濾規則時,過濾規則會被 libpcap 編譯成 BPC 虛擬機可以執行的 bpf program,然後載入到 kernal 的 BPF 虛擬機,BPF 擷取出來的封包也會被 libpcap 給接收,然後回傳給 tcpdump 顯示
tcpdump -d ip
透過 -d 這個參數,我們可以看到 ip 這個過濾規則會被編譯成怎樣的 BPF program
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 3
(002) ret #262144
(003) ret #0
- Line 0
ldh指令複製從位移 12 字節開始的 half word (16 bits) 到暫存器,對應到 ethernet header 的 ether type 欄位。

- Line 1
jeq檢查暫存器數值是否為0x0800(對應到 IP 的 ether type)- 是的話,走到 Line 2
return 262144 - 不是的話,跳到 Line 3
return 0
- 是的話,走到 Line 2
ret指令結束 BPF 並根據回傳值決定是不是要擷取該封包,回傳值為 0 的話表示不要,非 0 的話則帶表要擷取的封包長度,tcpdump 預設指定的擷取長度是 262144 bytes。
BPF 提供了一個高效、可動態修改的 kernal 執行環境的概念,這個功能不僅只能用在封包過濾還能夠用在更多地方,因此在 Linux kernal 3.18 加入了 eBPF 的功能,提供了一個“通用的”in-kernal 虛擬機。承接了 BPF 的概念,改進了虛擬機的功能與架構,支援了更多的虛擬機啟動位置,使 eBPF 可以用在更多功能上。
也因為 eBPF 做為一個現行更通用更強大的技術,因此現在提及 BPF 常常指的是 eBPF,而傳統的 BPF 則用 classic BPF (cBPF) 來代指。
eBPF 的應用#
在介紹 BPF 的時候,有提到 BPF 本身就是一個在 kernal 內的虛擬機。eBPF 在 kernal 的許多功能內埋入了虛擬機的啟動點 (hook point)。例如當 kernal 執行 clone 這個 system call 的時候,就會去檢查有沒有 eBPF 程式的啟動條件是等待 clone 這個 system call,如果有的話就會調用 BPF 虛擬機執行 eBPF 程式,同時把 clone 相關的資訊帶入到虛擬機。同時虛擬機的執行結果可以控制 kernal 的後續行為,因此可以透過 eBPF 做到改變 kernal 程式進程、數據,擷取 kernal 執行狀態等功能。
使用 eBPF 我們可以在不用修改 kernal 或開發 kernal module 的情況下,增加 kernal 的功能,大大了降低了 kernal 功能開發的難度還有降低對 kernal 環境版本的依賴。
這邊舉立一些 eBPF 的用途
in kernal 的網路處理:以往在 linux 上要實作網路封包的處理,通常都會經過整個 kernal 的 network stack,通過 iptables (netfilter), ip route 等組件的處理。透過 eBPF,我們可以在封包進入 kernal 的早期去直接丟棄非法封包,這樣就不用讓每個封包都要跑完整個 network stack,達到提高效能的作用
- 最知名的應該是 Cilium 這個 CNI 專案,基於 eBFP 提供了整套完整網路、安全、監控的 Kubernetees CNI 方案。
kernal tracing: 前面提到 eBPF 在 kernal 內的許多地方都埋入了啟動點,因此透過 eBPF 可以再不用對 kernal 做任何修改的情況下,很有彈性的監聽分析 kernal 的執行狀況
下圖是 bcc 專案使用 eBPF 開發的一系列 Linux 監看工具,基本涵蓋了 kernal 的各個面向。
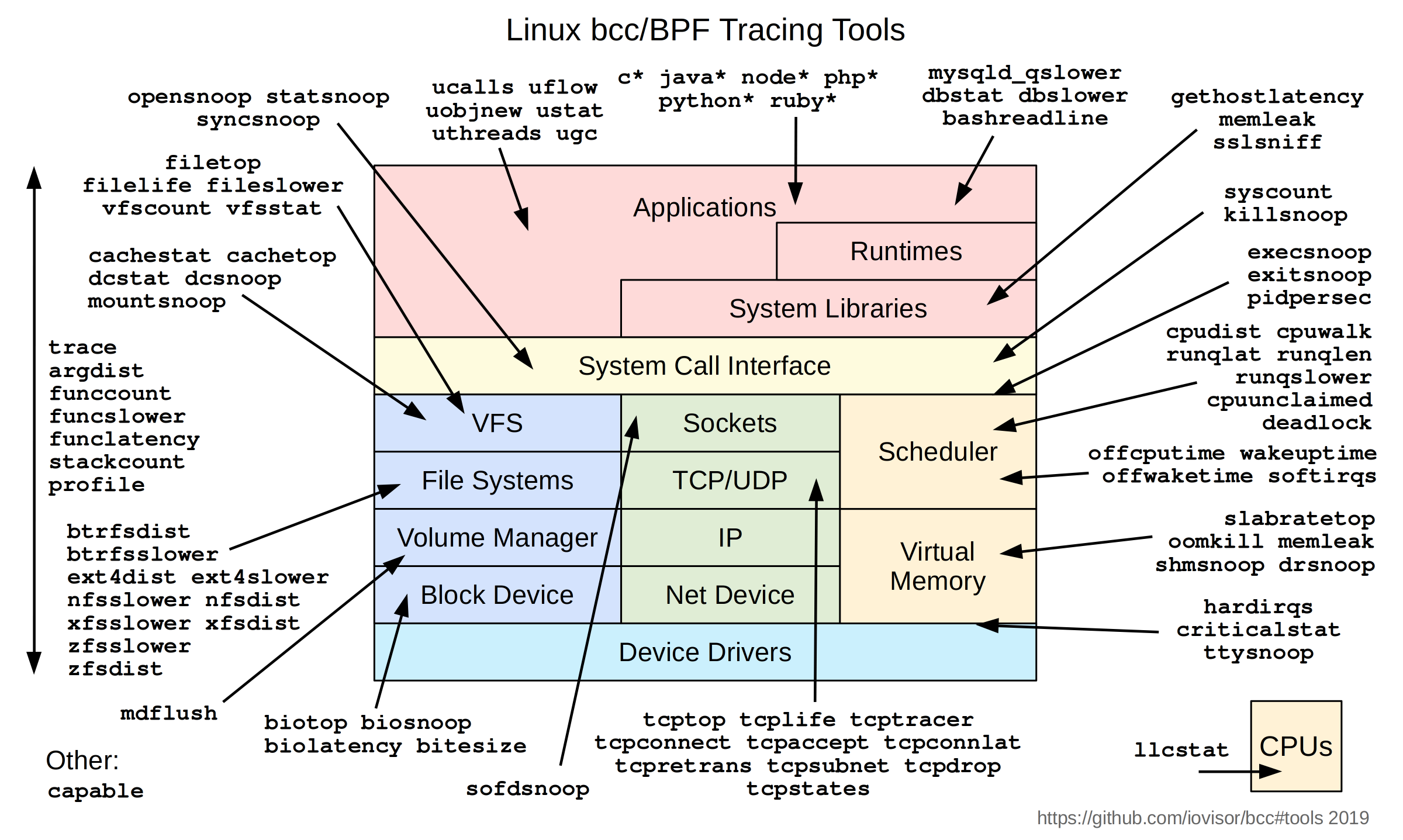
另外一個專安
bpftrace也提供了一個非常簡單的語法,來產生對應的 eBFP tracing code。user level tracing: 透過 eBFP,我們可以做 user level 的 dynamic tracing,來監看 user space 應用程式的行為。
- 一個很有趣的案例是我們可以使用 eBPF 來做 ssl 加密連線的監看。SSL/TSL 的連線加密通常是在 user space 應用程式內完成加密的,因此即便我們監看應用程式送入 kernal socket 的內容,內容也已經是被加密的了。但是要拆解應用程式來查看又相對比較複雜困難,使用 eBPF 就可以用一個相對簡單的方法來監看加密訊息。
- 在 Linux 上,應用程式的加密經常會使用 libssl 這個 library 來完成,並使用 libssl 提供的
SSL_read和SSL_write取代 socket 的read和write,透過 eBPF 的功能,我們可以比較簡單的直接監聽應用程式對這兩個函數的呼叫,並直接提取出未加密的連線內容。
Security: 前面有講到透過 eBFP,我們可以監控 system call 的呼叫、kernal 的執行、user space 程式的函數呼叫等等,因此我們也就可以透過 eBFP 來監控這些事件,並以此檢測程式的安全,拒絕非法的 system call 呼叫,或異常行為等等。 + 詳細可以參考
Tetragon和tracee之類的專案。
上面大概介紹了一些 eBFP 的應用場景,BPF 經過擴展之後,不再侷限於封包過濾這個場景,而在網路處理、内核追蹤、安全監控,等各個方面有了更多可以開發的潛能。